ローカルLLMを構築したい:モデルのパラメータの調整項目など

Open WebUIを使い倒すなら、モデルも色々いじれないとねと。
モデルの作成や管理方法、パラメータについて調べてみることにしました。
いやー。
ローカルLLMで良さそうなモデルまで調べる予定だったんですがー。
パラメータまででお腹いっぱいです。

モデルの管理画面
まずは、Open WebUIでのモデル管理画面までの行き方を。
左下のメニューから、管理者パネル➾設定➾モデルを選択します。
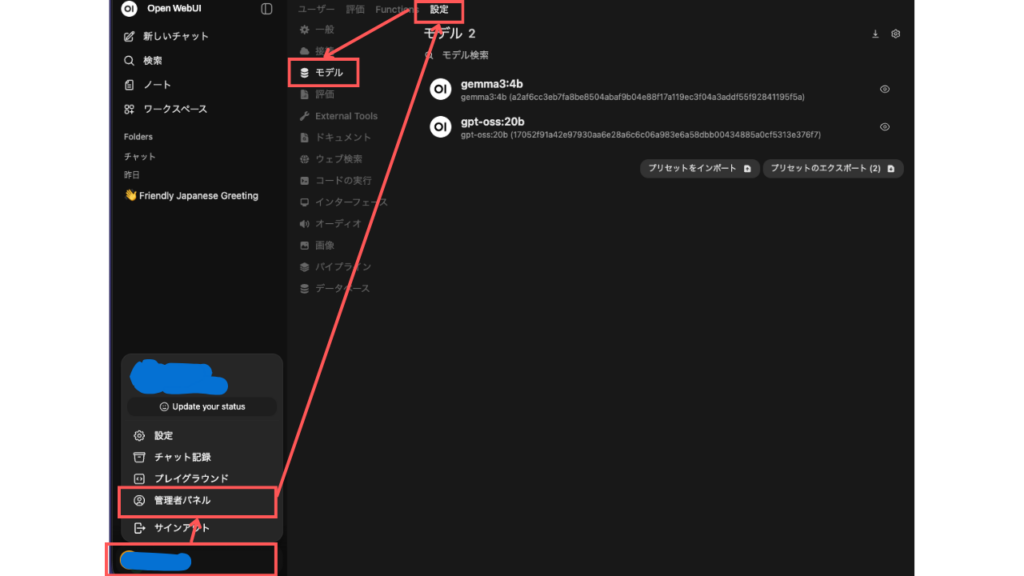
「モデル」と書いてあるタイトルのようなものの右端にある、ダウンロードボタンを押すと。
すでに保存されているモデルを選択したり、ダウンロードしたりできますね。
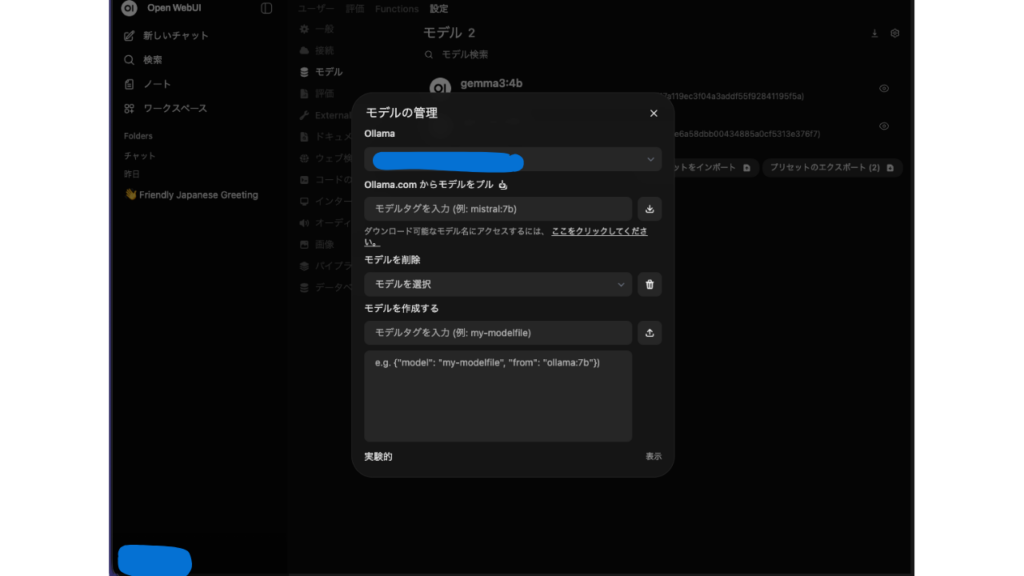
ダウンロードはOllama経由です。
ここ以外のものは、Hagging Faceなどでダウンロードして読み込ませます。
モデルのラッパーを設定する
Open WebUIで使用できるモデルは管理画面でリスト表示されていて。
モデル部分をクリックすると、詳細画面が表示されます。
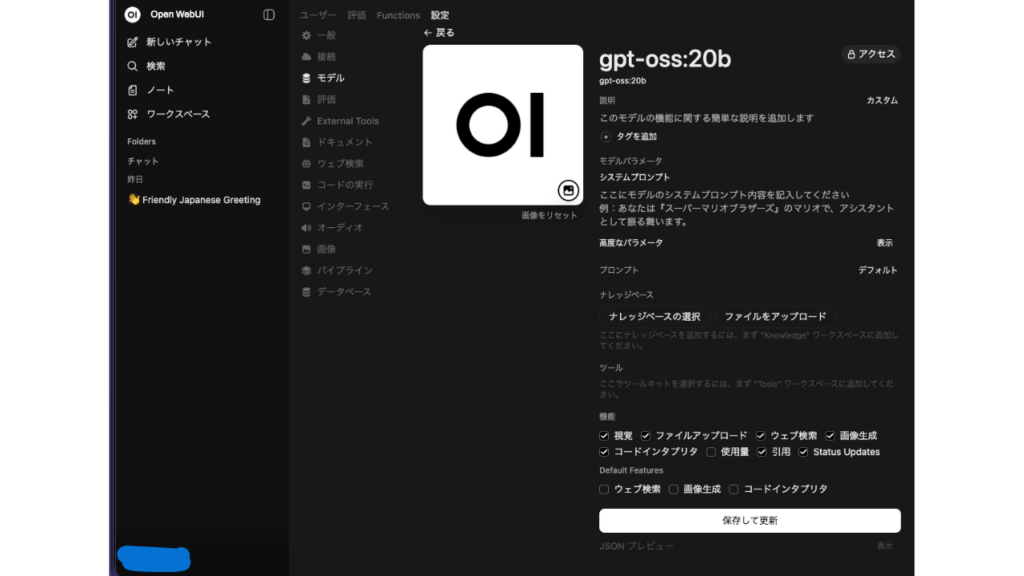
モデルの振る舞いを設定するので、ラッパーの作成と。
そういうことです。
| 名称 | 内容 |
|---|---|
| システムプロンプト | モデルの動作とペルソナの定義 |
| 高度なパラメータ | 推論生成の微調整。後述。 |
| プロンプトサジェスト | 入力フォームの上部に表示されるもの ・モデルの機能説明 ・ショートカットの作成 |
| ナレッジベース | 特定のナレッジベースやファイルをRAGとして自動で認識させる |
| ツール | 外部ツールをデフォルトで有効にする |
| 機能 | モデルに許可する操作を設定 ◯視覚:画像分析機能のON・OFF ◯ファイルのアップロード: ユーザーがモデルにファイルをアップロードできるようにする。 ◯コードインタプリタ:Pythonコード実行のON・OFF ◯画像生成:画像生成の統合のON・OFF ◯使用状況/引用:使用状況の追跡またはソースの引用を切り替える ◯Status Updates:生成中に進捗状況を表示する |
| Default Features | 以下の強制的にONにするかどうか ◯ウェブ検索 ◯画像生成 ◯コードインタプリタ |
Default Featuresの項目は、入力フォームのひし形のところで選択できる項目ですね。

基本的な動作や機能はここで設定できますと。
そして、LLMの推論の内容は「高度なパラメータ」というところでチューニングできます。
今回のメインはここです。
高度なパラメータ
クリックして開くと、グワッとパラメータが並びます。
以下の内容です。
| パラメータ | 内容 |
|---|---|
| チャットレスポンスのストリーム | ユーザーのメッセージ送信と同時に応答を生成。 ライブチャット向けだが、性能が低いと動作が重くなる。 |
| ストリームのチャンクサイズ | モデルがストリームするテキスト差分のチャンクサイズ。 増やすと1回の送信量が増える。 |
| Function呼び出し | デフォルト:実行前に呼び出す。広範なモデルで動作 ネイティブ:モデルの組み込みツールの呼び出し機能を活用 |
| 推論タグ | 有効:デフォルトのタグを使用 無効:オフ カスタム:独自の開始・終了タグを指定できる |
| シード | 同じプロンプトであれば、同じテキストを生成する |
| ストップシーケンス | テキスト生成を停止するプロセスを設定 |
| 温度(temperature) | 上げると創造的に回答する |
| 推論の努力 | モデルが最終的な応答を決定する前に、 どのくらい時間をかけて思考するかを設定 |
| logit_bias | 特定のトークンの強調またはペナルティの適用。 -100~100で設定。 |
| max_tokens | 生成できるトークンの最大数 増やすと長い回答を生成できるが、 不適切な表現や関連性の低い内容を含む可能性がある。 |
| top_k | 無意味な生成の確立を減少させる 高いと多様で、低いと保守的 |
| top_p | top_kと併用する。0~1で設定 |
| min_p | top_pの代替値。品質と多様性を確保するための値 p:最も確率の高いトークンの確率に対する、 トークンが考慮される最小確率 例: p=0.05 最も可能性が高いトークンの確率=0.9 ➾0.045未満の確率のトークンをフィルタリングする |
| freqency_penalty | 出現回数に応じ、トークンにスケーリングされた ペナルティを設定 高い:繰り返しの抑制 低い:寛容 0:無効 |
| presence_penalty | 一度でも出現したトークンに一定のペナルティを設定 |
| mirostat | 意外性・多様性を制御するサンプリング値 人間らしい文章を生成するためのパラメータ |
| mirostat_eta | どれだけ新しい情報を取り入れさせるかの「学習率」の設定 フィードバックに対する応答速度に影響 |
| mirostat_tau | 出力のコヒーレンスとdiversityのバランスを制御する 値が高いほど、一貫性のあるテキストを生成 生成中のフィードバックループを使用し、 サンプリングパラメータを動的に調整することで、 長文生成でも一貫性を保持するためのパラメータ |
| repeat_last_n | モデルの繰り返し防止のために、遡る履歴の長さ |
| tfs(Tail Free Sampling) | 確率の低いトークン(=Tail)の影響を減らす 出力のランダム性を調整する ※他のサンプリングパラメータと併用不可 |
| repeat_penalty | 生成されたテキストのトークンシーケンスの繰り返しを制御 高い:ペナルティ 低い:寛容 1:無効 同じものを繰り返すような、 不自然な繰り返しを制御することができる |
| use_mmap | モデルデータのロードにメモリマッピングを有効にする ディスクストレージをRAMの拡張として使用 パフォーマンスは向上するが、 ディスク容量をかなり消費する |
| use_mlock | モデルデータがRAMからスワップアウトされるのを防ぐ ページフォールトを回避し、パフォーマンス向上 |
細かく動作を設定できるんだなぁという印象ですね。
どちらかと言うと、Open WebUIを利用してAIアプリを作る時にいじる内容でしょうか。
各パラメータにマウスカーソルを合わせると、上記のような詳細を確認できます。
が、G検定の勉強を思い出しながら作成しました。

モデルの微調整もできる
ローカルLLMの醍醐味は、やはり自分専用のLLMを持てることですよねぇ。
ChatGPTなどでもシステムプロンプト等でできますが。
遊んだり試しながら設定できるのが良いところ!
・・・という意気込みで調べ始めたものの。
思ったより細かくて驚きました。
使い倒せるように調整を進めたいですねぇ。

このブログや記事の内容について、疑問に思っている事はありますか?
もしあれば、どんなことでも構いませんので、コメントを残していただくか、問い合わせフォームよりご連絡ください。

はじめまして、「ぽんぞう@勉強中」です。
小企業に一人情報部員として働いている40代のおじさんです。IT技術での課題解決を仕事にしていますが、それだけでは解決できない問題にも直面。テクノロジーと心の両面から寄り添えるブログでありたいと、日々運営しています。詳しくはプロフィールページへ!